
Session discrepancies – Universal Analytics, GA4 & BigQuery
We are closing in on the sunsetting of the standard version of Universal Analytics, and many of you have probably started using data from Google Analytics 4. One thing you probably have noticed is that the data isn't completely matching between Universal Analytics, Google Analytics 4 and the BigQuery export.
In this post we will delve into the different factors that might create these discrepancies, and what you should do about it. There are a lot of posts out there explaining what GA4 is and how it works different from Universal Analytics. Therefor, we will focus mainly on the actual discrepancies that you should be aware of.
It's worth mentioning that much of the content within this article is under constant change, since GA4 is constantly receiving updates and new features. Therefor, I apologize if some of the content might be outdated when you read this. The article is written on February 1, 2023.
Why are the sessions different in GA4 than UA?
This might be the most common question we hear from customers who have started working actively with GA4. So let's look at how the different tools define how a session breaks or forces a new session to begin.
Universal Analytics
- 30 minutes of inactivity (or custom set timeout expiration)
- A new day begins (session occurring past midnight)
- A new non-direct traffic source is registered (e.g. Google Ads identifier, UTM etc)
Google Analytics 4
There are a few other situations that can break a session too, but these ones are the most common, and probably the reason for the differences. If you have many users who visit your website during midnight hours (and think about the time zone difference in the account) this will decrease the amount of users by quite a lot. The most probable cause of the session discrepancies is the fact that new sources are no longer creating new sessions. The following examples would create a new session in UA, but not in GA4:
- 30 minutes of inactivity (or custom set timeout expiration)
- A user goes back to the Google result page and clicks on another link to the website.
- A user clicks on a link on the website tagged with UTM parameters (you should never do this, but I know some websites do have it).
- A user is navigating the website and then remembers that he/she received a link in an email for a special offer. When clicking the email a new session starts even though it happens in the same browser.
- A payment provider directs the user to an external domain to verify a purchase and then directs them back to the website. These domains should be excluded in UA settings, but if they're not, they will create new sessions.
As we can see in the examples above, in most cases Universal Analytics counts more sessions than GA4. However, there is one situation where GA4 will actually create a lot of unwanted sessions.
Inactive visitor comes back
When a visitor leaves a tab for more than 30 minutes, the session will break, as stated above. When the visitor returns to the tab, the browser indicates that there is engagement. In UA/GA3, this information wasn't collected. The visitor would have to refresh the page to send any data to GA. In GA4, however, we have an event called "user_engagement" that will fire when this happens. Since the event would be sent without any previous activity, due to the session timeout, a new session would be created, but wouldn't contain anything other than the "user_engagement" event. If you've implemented BigQuery, it's quite simple to check how many of the sessions are represented by this sort of behavior.
Session count difference
There is also another important difference between UA and GA4. In UA, a session would only be counted once, when the session actually started. In GA4, a session is considered a session if there is an event within the chosen time frame. This means that GA4 will include sessions that started the day before the selected time period if they continued past midnight.
Internal IPs
One last thing worth mentioning is that you should check if you've added the same exclusions of IP addresses in GA4 as you are using in UA.
Shouldn't sessions be the same in GA4 and BigQuery?
One of the greatest features with Google Analytics 4 is the possibility to link the data to Google BigQuery. You could do this in Universal as well, but only if you had a 360 license. Now it's free up to 1M events per day. What the linking does is that it extracts the raw data from Google Analytics 4 and stores it in a dataset in BigQuery, where you can query the data. Since the data is streamed from GA4 you would expect it to contain the exact same information, wouldn't you? Well not in the world of Google. There are actually some very important concepts to be aware of when working with the BigQuery dataset.
Session count
As mentioned in a previous section, GA4 counts sessions based on at least one event occurring in the selected time frame. This means that if you query data on a daily basis, you might count the same session multiple times when it occurs past midnight. This could be avoided by for example counting sessions in BigQuery by the first event sent for the session. You would have to use a lookback window that goes back a day further than the time period you want to query to avoid missing the first event for the session. A recommendation that we are using is to create a separate lookup table in BigQuery that contains all sessions based on the first occurrence which then could be used to get the session start date.
GA4 is not showing actual data
This might come as a shock if you haven't heard it before, but GA4 is not showing you a 100% of the data, even if they say they do.

After working in Universal, you probably believe that when the notice says that no sampling has occurred, you can trust the data to be accurate. The fact is that Google has built GA4 to be faster than its predecessor, and one of the things they've done to achieve this is to estimate sessions. They haven't really communicated this in a clear way, but there is documentation to be found: https://developers.google.com/analytics/blog/2022/hll.
I'll spare you the time to read through it all, and instead summarize the important parts. They are using an algorithm called HLL++ that is built on another algorithm called HyperLogLog. What it does is that it estimates cardinality in a large dataset based on a smaller amount of the data, which it then uses to pretty much guess the unknown part of the data. I'm not gonna lash out completely on this, since it usually performs pretty good. If you have a lot of traffic on your website, this might actually be a good idea to implement yourself in your BigQuery data as well, which is possible with the function APPROX_COUNT_DISTINCT in your SQL query. You can read more on it in the link above.
However, if you choose to query the raw data as it is, you will, without a doubt, find discrepancies between your GA4 data and your BigQuery data.
Other reasons for different data in BigQuery vs GA4
There are a lot of factors that might affect the data, but I'll give you some examples worth thinking about:
- What are you querying in BigQuery? Does it represent the same thing as in GA4?
- Custom parameters are not included in auto events created by GA4, such as "session_start".
- Time zone differences might influence the data. Make sure that you are viewing the same time frames.
- GA4 might sample your data, while BigQuery contains everything.
- GA4 might apply a threshold of your data to avoid showing anything personal.
- Google Signal is not exported in the BigQuery stream, which might also affect the presented data.
Google Consent Mode
Is it already starting to feel like a jungle? Sorry to disappoint you, but we haven't even started with the toughest part yet; Google Consent Mode. I think we need to start by explaining what this is before we go into the problems it might create.
What is Google Consent Mode?
The amount of information regarding what this is and how it works is overwhelming. Just kidding, it's really surprising how little information about this Google has produced. You can find some documentation on it on the pages linked below, but I'll summarize the important parts.
- https://support.google.com/analytics/answer/9976101
- https://support.google.com/analytics/answer/11161109
Google Consent Mode, or GCM for short, was introduced in order to allow website and app owners to be able to use Google Analytics and Google Ads even if the user didn't consent to the use of cookies. Google claim that this service is fully compliant with regulations such as the GDPR. Neat, right? Now we don't have to lose track of all those visitors who didn't want to accept our annoying cookie pop up, which if we're being honest, we tried to force everyone to accept, yes I'm looking at all of you marketing managers. Now, you can include them even if they refuse.
Okay, so does that sound to good to be true? Well, both yes and no. Technically, the solution prevents any cookies or local storage to be used on the device. However, is that really the important thing when it comes to privacy? Should you really send data directly to Google just because of a technicality? If the user didn't want to be tracked, do you think it's ethically correct to track them anyway? Also, it's not only cookies that are considered personal information. What about the IP address, user agent, etc. Just turning it on with the argument that "Google says it's compliant" might not hold up as well in court as you might think. But let's not get into the legal perspective more than that. I could talk about it for hours, but the key thing here is how it affects your data.
So the way that Google can send this information without storing anything on your device is that they are using pings instead. This means that they will not be able to follow your behavior on a website. All events will be sent without any persistent user identifier, meaning you will not be able to analyze the behavior of the non consented users.
What happens with the users who don't opt in
I'm gonna start off with the most frustrating fact here; UA, GA4 and BigQuery all handle this in separate ways. Now let's look at the differences in detail.
Universal Analytics
Universal Analytics will not store any data sent with denied consent in GCM. This means that users who do not opt-in to tracking will not be accounted for in the statistics.
Google Analytics 4
GA4 will handle both users who opted in and users who did not. Since the interface show the total amount of events, the data is aggregated. But hold on, I mentioned earlier that the users who don't opt in aren't registered with a persistent identifier. How could GA4 aggregate the data when there is no way to know what specific users did during the visit? For example, how can GA4 tell that users from Google Ads made X transactions? Well, one thing that Google has communicated a lot regarding GA4 is AI. They rely heavily on modeled data. The model is based on the known visitors and then applied on the unknown to estimate what the expected behavior would be. As you probably can guess, this means that the data isn't exactly 100% reliable.
One thing we've seen is that the estimates produced by the modeling sometimes can be misinterpreted. For example, when we investigated specific traffic types, we noticed that the behavior from users who clicked on display advertising was estimated to have performed much better than in reality. This modeling is a work in progress, so we can only hope it performs better and better the longer it is used. But the fact that this modeling occurs in combination with the estimation calculation, that was mentioned previously in the article, it creates a risk that the data within the GA4 interface does not reflect reality.
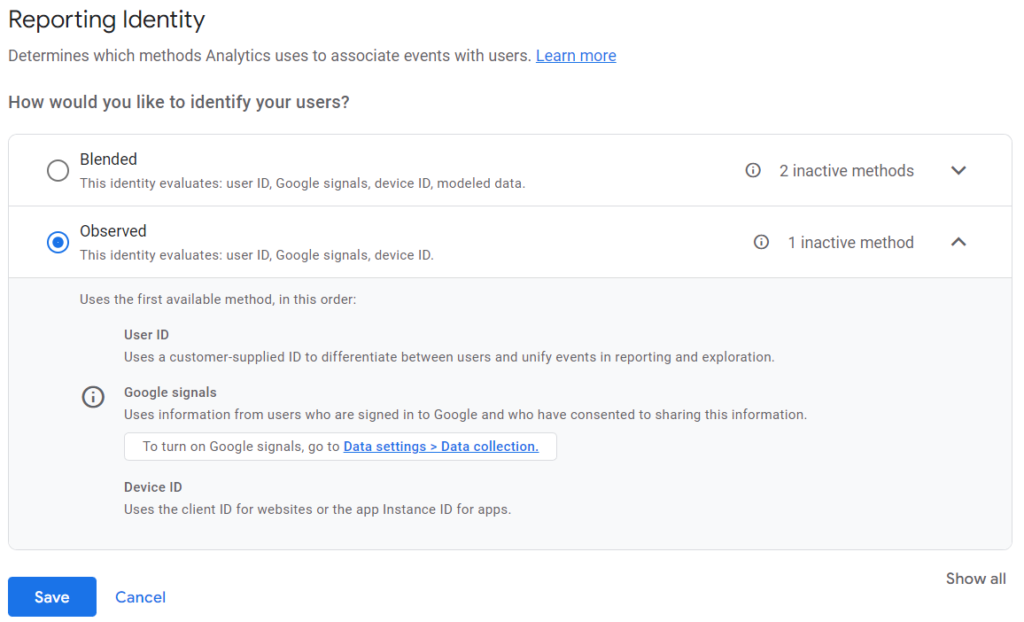
The good thing is that you can choose if you want to include the modeled data in the reports or skip it. There is a setting available if you open the admin section. It's under the property settings column and is called Reporting Identity. Here you can choose whether to use the modeled data or only the observed. This does not affect the underlying data, so you can switch this setting without accidentally deleting something.
BigQuery
In BigQuery, we get the raw data, which means that all events will be sent to the dataset. The difference between the opted in users and the ones who have not is that there are no identifiers for the non-opted in users. There are also other columns missing data, for obvious reasons. One example are the traffic source columns. They can't contain data since the events are sent in silos and can't be connected to the original UTM parameters. However, the information needed to create your own traffic source data could be obtained from the event parameters for the event "session_start".
Since all the events are registered in BigQuery with the information available depending on opt in status of the user, it is the best source of truth. The thing that will probably give you a headache is when you aggregate the data for the non-opted in users. If you don't use a similar method as Google themselves are doing for GA4, you might end up with large discrepancies in grouped data from your BigQuery tables and the GA4 interface.
One thing worth mentioning is that if a user is opting in after viewing for example three pages of your website, the identifier for the user will automatically be inserted for the previous events during the same session as well.
Conclusion
To summarize the problem with discrepancies, you could say that it is expected to see different numbers of sessions in the different platforms, since they have different ways of defining what a session is. The differences between BigQuery and GA4 can be avoided if you decide to run calculations in BigQuery the same way as the GA4 interface is doing, but I would recommend to use the actual data in BigQuery to create your own smaller tables with the key data you're interested in with actual data and not estimated.
If you have Google Consent Mode turned on, the differences are much worse, if you don't change the default settings in reporting identity and also depending on how you query the raw data in BigQuery.
The most important thing is to decide what your source of truth will be when it comes to web analytics and use that for all reporting purposes. You can still use both GA4 and BigQuery, but make sure to decide what the purpose of the tool should be and make sure all your employees share that view and understanding.
Linus Larsson
Digital Analyst